Scraping Web Pages with Scrapy
This is a simple tutorial on how to write a crawler using Scrapy to scrape and parse Craigslist Nonprofit jobs in San Francisco and store the data to a CSV file.
If you don’t have any experience with Scrapy, start by reading this tutorial. Also, I assume that you are familiar with Xpath; if not, please read the Xpath basic tutorial on w3schools. Enjoy!
Updates:
- 09/18/2015 – Updated the Scrapy scripts
Be sure to check out the accompanying video!
Contents
Installation
Start by downloading and installing Scrapy (v0.16.5) and all its dependencies. Refer to this video, if you need help.
Create a Project
Once installed, open your terminal and create a Scrapy project by navigating to the directory you’d like to store your project in and then running the following command:
$ scrapy startproject craigslist_sample
Item Class: Open the items.py file within the “craigslist_sample” directory. Edit the file to define the fields that you want contained within the Item. Since we want the post title and subsequent URL, the Item class looks like this:
from scrapy.item import Item, Field
class CraigslistSampleItem(Item):
title = Field()
link = Field()
The Spider: The spider defines the initial URL (http://sfbay.craigslist.org/npo/), how to follow links/pagination (if necessary), and how to extract and parse the fields defined above. The spider must define these attributes:
- name: the spider’s unique identifier
- start_urls: URLs the spider begins crawling at
- parse: method that parses and extracts the scraped data, which will be called with the downloaded Response object of each start URL
You also need to use the HtmlXpathSelector for working with Xpaths. Visit the Scrapy tutorial for more information. The following is the code for the basic spider:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from craigslist_sample.items import CraigslistSampleItem
class MySpider(BaseSpider):
name = "craig"
allowed_domains = ["craigslist.org"]
start_urls = ["http://sfbay.craigslist.org/search/npo"]
def parse(self, response):
hxs = HtmlXPathSelector(response)
titles = hxs.select("//span[@class='pl']")
for titles in titles:
title = titles.select("a/text()").extract()
link = titles.select("a/@href").extract()
print title, link
Save this in the “spiders” directory as test.py.
Test
Now you are ready for a trial run of the scraper. So, while in the root directory of your Scrapy project, run the following command to output the scraped data to the screen:
$ scrapy crawl craig
Dicts: The Item objects defined above are simply custom dicts. Use the standard dict syntax to return the extracted data inside the Item objects:
item = CraigslistSampleItem()
item["title"] = titles.select("a/text()").extract()
item["link"] = titles.select("a/@href").extract()
items.append(item)
Release!
Once complete, the final code looks like this:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from craigslist_sample.items import CraigslistSampleItem
class MySpider(BaseSpider):
name = "craig"
allowed_domains = ["craigslist.org"]
start_urls = ["http://sfbay.craigslist.org/search/npo"]
def parse(self, response):
hxs = HtmlXPathSelector(response)
titles = hxs.xpath("//span[@class='pl']")
items = []
for titles in titles:
item = CraigslistSampleItem()
item["title"] = titles.select("a/text()").extract()
item["link"] = titles.select("a/@href").extract()
items.append(item)
return items
Store the data
The scraped data can now be stored in these formats- JSON, CSV, and XML (among others). Run the following command to save the data in CSV:
$ scrapy crawl craig -o items.csv -t csv
You should now have a CSV file in your directory called items.csv full of data:
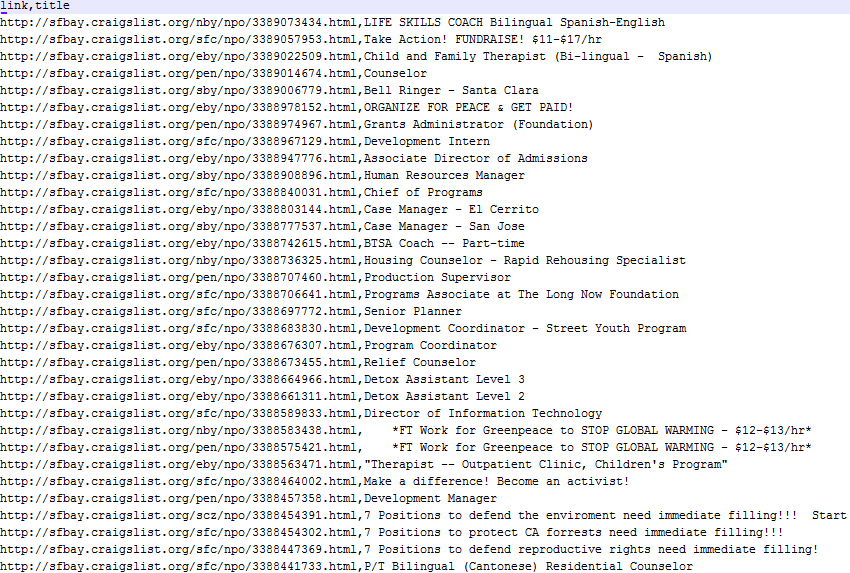
Although this is relatively simple tutorial, there are still powerful things you can do by just customizing this basic script. Just remember to not overload the server on the website you are crawling. Scrapy allows you to set delays to throttle the crawling speed.
Next time
In my next post I’ll show how to use Scrapy to recursively crawl a site by following links. Until then, you can find the code for this project on Github.